Classification Technique
The classification technique is the way of developing a model that defines and separates several data classes from each other. Initially, the classification procedure applies some preprocessing tasks (data cleaning, data transformation etc.) to the original data set. Then, the method divides this preprocessed data set into two different sections namely the training data set and the test data set. A classification technique creates a classification model which is alternatively known as a classifier.
Classification contains two different steps. The first step builds a classification model indicating a well-defined set of classes. Therefore, this is the training phase, where the classification technique constructs the model by learning from a given training data set accompanied by their related class label attributes. After that, the classification model is applicable for classification called the testing phase. This step estimates the performance of the derived model using the test data set.
Classification is a predictive data mining task. Uses of classification in real world applications include:
- Image classification
- Disease detection
- Email spam detection
- Bank loan prediction
- Speech recognition
- Face Detection
A classification model can use several procedures, such as mathematical formulas, simple if-else rules, artificial neural networks, or decision trees.
The broad level stages of the classification technique are described here in details.
Step 1: Several preprocessing techniques are applied to the sample data set before the classification task —
Step-1a. Data cleaning: It represents the preprocessing of data for eliminating or decreasing noise and the treatment of missing values. A missing value for a numeric column is normally substituted by the arithmetic mean for that attribute based on statistics.
Step-1b. Data transformation: Using this way the data set is normalized as because the ANN based technique requires distance measurements in the training phase. It converts attribute values to a small-scale range like -1.0 to +1.0.
Step 2: Afterwards, the preprocessed data set is distributed into two sub-sets, namely the training set and the test set.
Step 3: ML based classification algorithm is applied to the training set for building a classification model / classifier.
Step 4: The classifier is then employed to the test data set for evaluating its performance.
Step 5: The performance evaluation of the classifier is then done on the basis of different performance measures like accuracy, root-mean-squared error, kappa statistic, precision, recall, and f-measure value.
The broad level stages of the classification procedure are depicted below in Figure 1 for better understanding of the whole process.
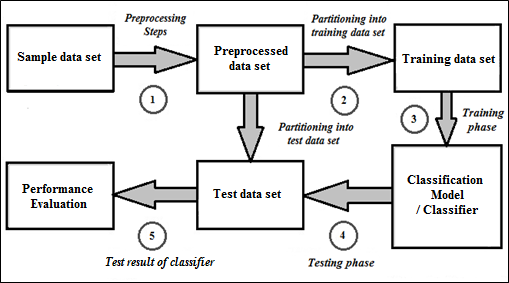
Figure 1: Broad level stages of the classification procedure
The performance of a classification model depends on the following criteria:
Accuracy: The classification accuracy or accuracy of a classification model denotes its capability to forecast the class label of new or previously unknown data appropriately.
Speed: This means the computational costs required to develop and use a given classification model or classifier.
Robustness: This is the ability of a classification model to make correct predictions in the presence of noisy data or data with missing values.
Scalability: This denotes the capability to build a classification model proficiently given vast amount of data.
Interpretability: This indicates the level of comprehension and vision that is offered by a given classification model.
In the next segments, I will discuss about some of the well-known classifiers in the machine learning domain such as MLP (ANN), DT, SVM etc.