Types of Machine Learning
Machine Learning (ML) provides computer systems the capability to learn and improve automatically from experiences and examples without being explicitly programmed. ML is a subset of Artificial Intelligence (AI).
Basically, ML allows the computer systems to make decisions independently without any external help. These decisions are made when the system is able to learn from the example data and understand the underlying patterns that are contained within it. Then, through pattern matching and further analysis, the system arrives at a decision.
ML is divided into three broad categories —
1. Supervised learning
2. Unsupervised learning
3. Reinforcement learning
They are now described one-by-one below.
1. Supervised Learning
Supervised learning is the most popular paradigm for performing machine learning operations. It is widely used for datasets where there is a precise mapping between input-output data. The dataset, in this case, is labeled, meaning that the algorithm identifies the features explicitly and carries out predictions or classification accordingly. As the training period progresses, the algorithm is able to identify the relationships between the two variables such that we can predict a new outcome.
Supervised learning is the one, where we can consider the learning is guided by a teacher. We have a labeled dataset which acts as a teacher and its role is to train the model or the machine. Once the model gets trained it can start making a prediction or decision when new data is given to it. As because supervised learning relies on predefined classes and class-labeled training examples, it is often described as learning by examples.
Some of the important algorithms that come under Supervised Learning are given below:
- Artificial Neural Network (ANN)
- Support Vector Machine (SVM)
- Decision Tree (DT)
- K-Nearest Neighbor (KNN)
- Random Forest
- Linear Regression
- Logistic Regression
2. Unsupervised Learning
In the case of unsupervised learning algorithm, the data is not explicitly labeled into different classes, that is, there are no labels. The model is able to learn from the data by finding implicit patterns. Unsupervised Learning algorithms identify the data based on their densities, structures, similar segments, and other similar features.
Cluster analysis is one of the most widely used techniques in unsupervised learning as there is no teacher to guide the process (i.e. datasets are unlabeled). The model learns through observation and finds structures in the data. Once the model is given a dataset, it automatically finds patterns and relationships in the dataset by creating clusters in it. That is why we can say that unsupervised learning is based on learning by observation.
Some of the important algorithms that come under Unsupervised Learning are given below:
- Clustering (e.g. k-Means, k-Medoids, Hierarchical)
- Association Rule Mining (e.g. Apriori, FP-Growth)
- Neural Network (e.g. autoencoder, self-organizing maps)
Principal Component Analysis (PCA)
3. Reinforcement Learning
Reinforcement learning is fairly different when compared to supervised and unsupervised learning. Whereas, we can easily see the relationship between supervised and unsupervised (by the presence or absence of labels), the relationship to reinforcement learning is quite different. It actually depends on the concept of agent based learning. This is quite similar to the idea of learning in the presence of a critic. The agent is rewarded or penalized by the critic with a point for a correct or a wrong answer, and on the basis of the positive reward points gained the model trains itself. And again once trained it gets ready to predict the new data presented to it.
Reinforcement learning can be considered as learning from mistakes. We place a self-driving car based on reinforcement learning algorithm into any environment and it will make a lot of mistakes in the beginning. So long as we provide some sort of signal by using agents to the algorithm that associates finding correct paths with a positive signal and finding wrong paths with a negative one, we can reinforce our algorithm to prefer correct paths over wrong paths. So, it is basically the ability of an agent to interact with the environment and find out what is the best outcome. Over time, the learning algorithm learns to make less mistakes than it used to.
The different types of machine learning is shown in Figure 1 below.
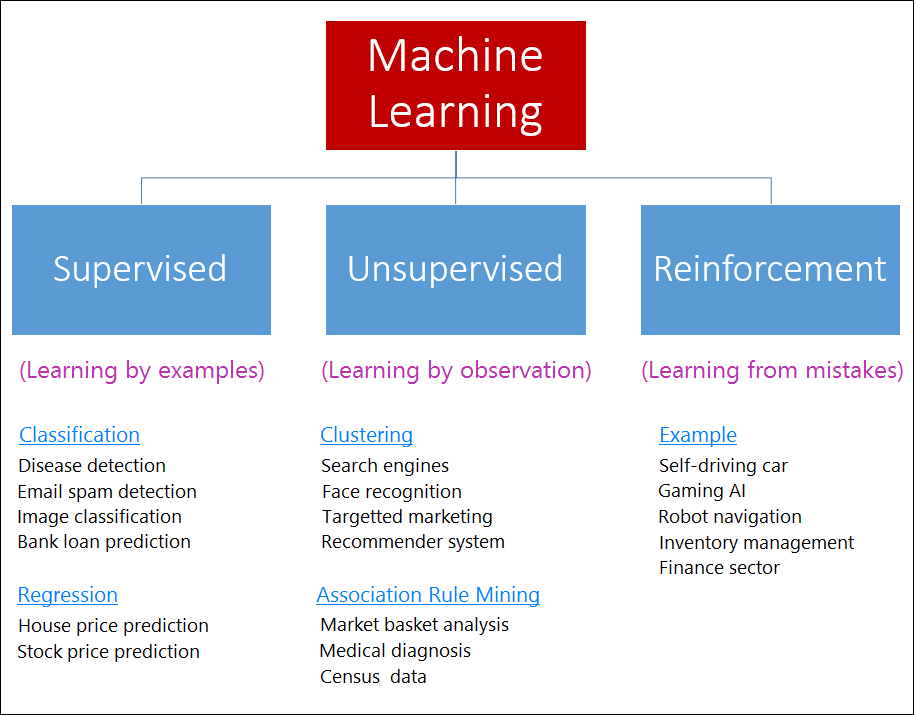
Figure 1: Types of Machine Learning
In the next segments, I will discuss about the following techniques with Python coding implementation (in sequence):
- Classification (ANN, DT, SVM etc.)
- Regression (Linear, Polynomial etc.)
- Cluster analysis (k-Means algorithm)
- Association Rule Mining (Apriori algorithm)